相関

相関(そうかん 英:correlation)とは、一方が変化すれば他方も変化するように相互に関係しあうことである。数学や物理学では、二つの変量や現象がある程度相互に規則的に関係を保って変化することをいう[1]。因果性の有無は問わない。広義には、統計的に何らかの関連性があることを言うが、実際には二変数における線形性相関の程度を指す。例えば「親の身長が高いほうが子供の身長も高い」「勉強時間が長いほうがテストの成績も上がる」などの傾向が身近な相関現象である[2]。
相関は、実践で活用できる予測的な関係性を示してくれるため実用性がある。例えば、電気事業者は電力需要と天候との相関関係に基づいて、過ごしやすい気温の日には電力を少なめに発電したりもする。この例では、猛暑や厳寒といった極端な天候は人々が大量に電気を使う原因となるため、因果関係にあたる。ただし一般には、相関があっても因果関係があるとは言い切れない(すなわち相関関係は因果関係を含意しない)。
本質的に相関とは、2つ以上の変数が互いにどの程度関わり合っているかの尺度である。幾種類かの相関係数があり、多くの場合またはで表記される。統計学では、主に二変数の線形性相関に着目して関係性の強弱を係数で表しており、その最も一般的な尺度がピアソンの積率相関係数である(より堅牢なスピアマンの順位相関係数などは非線形相関にも対応する)[3][4][5]。


ピアソンの積率相関係数
詳細は「ピアソンの積率相関係数」を参照
カール・ピアソンが考案した積率相関係数は[6]、2変数間の相関を示す尺度として最もよく知られており、単に「相関係数」と言えば通常は「ピアソンの積率相関係数」を指す。数学的には、2変数の共分散を標準偏差の積で除算するだけで得られる。
ピアソンの相関係数は、実際のデータ群が期待値からどの程度外れているかを示すもので、-1から+1までの値で表される。データ群の変数間に何らかの線形的な関係性があれば、数値に正または負の符号がつき[注釈 1]、無相関であれば値は0になる。
2つの確率変数をと、各々の期待値をと、そして標準偏差をととすると、母集団の相関係数は次のように定義される。







|
|
![{\displaystyle \rho _{X,Y}=\operatorname {corr} (X,Y)={\operatorname {cov} (X,Y) \over \sigma _{X}\sigma _{Y}}={\operatorname {E} [(X-\mu _{X})(Y-\mu _{Y})] \over \sigma _{X}\sigma _{Y}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/93185aed3047ef42fa0f1b6e389a4e89a5654afa)
ここでのは期待値の作用素、は共分散を意味し、は相関係数の代替表記として広く使われている。ピアソン相関は、両方の標準偏差が有限かつ正の値である場合にのみ定義される。積率の観点から、次の式に書き改めたりもする。




対称性
この相関係数は対称性があり、である。これは乗算の可換性によって証明される。

積のような相関
確率変数との標準偏差をととすると、次のことが言える。


|
|

相関と独立
ピアソン相関係数の値は-1から+1の範囲をとり、完全な正の線形相関にあれば+1、完全な負の相関関係にあれば-1になる。それ以外の場合は-1から+1の範囲内にある何らかの値をとり、変数間における相関の強弱度合いを表す。値がゼロに近いほど関係性が乏しい(無相関に近い)ことになり、-1や+1に近いほど強い相関があることになる[8]。
変数同士が独立 (確率論)である場合[注釈 2]ピアソン相関係数は0となる。ただしピアソン相関係数は2変数間の線形相関のみを検出するため、この逆が真とは限らない。
|
|

例えば、確率変数が対称分布でだとする。その場合は完全にによって決定されるためとは完全に従属だが、線形相関のみを検知するピアソン相関係数では0となる。同様に、ピアソン相関係数が+1や-1に近い値を示したからといって、必ずしも2変量に関係性があるとは限らない。偶然にも相関があるかのような+1や-1に近い係数になることがあり、これは疑似相関(見せかけの相関)と呼ばれる[8]。なお、とが正規分布という特殊なケースだと、無相関は独立と同義である。

無相関のデータが必ずしも独立を含むとは限らないが、相互情報量が0であれば確率変数が独立しているかどうかを確認可能である。
例
下のようなとの同時確率分布を考える。








この同時分布の場合、周辺分布は以下のようになる。


ここから以下の期待値および分散値が得られる。




したがって、相関係数は次の通り。
![{\displaystyle {\begin{aligned}\rho _{X,Y}&={\frac {1}{\sigma _{X}\sigma _{Y}}}\operatorname {E} [(X-\mu _{X})(Y-\mu _{Y})]\\[5pt]&={\frac {1}{\sigma _{X}\sigma _{Y}}}\sum _{x,y}{(x-\mu _{X})(y-\mu _{Y})\operatorname {P} (X=x,Y=y)}\\[5pt]&=(1-2/3)(-1-0){\frac {1}{3}}+(0-2/3)(0-0){\frac {1}{3}}+(1-2/3)(1-0){\frac {1}{3}}=0.\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/fad47e7f832988fd44ed504e358fa404ee0bb341)
(すなわち「無相関」である)
確率変数間の従属を表す別の尺度
ピアソン相関係数によって与えられる情報だけでは、確率変数間の従属[注釈 2]構造を定義するのに十分ではない[10] 。この相関係数は、分布が多変量正規分布の場合など、非常に特殊な場合にのみ従属構造を完全に定義する。楕円分布の場合、それは等密度の楕円という特性を有する。ただし、従属構造を完全に特徴付けるわけではない。
距離相関 (Distance correlation) [11][12]は、従属確率変数についてゼロになりうるというピアソン相関の欠陥に対処する目的で導入された。距離相関のゼロは独立性を意味する。
確率的依存係数(Randomized Dependence Coefficient,RDC)[13] は、計算効率の良い多変量確率変数間のコピュラ (統計学)に基づく依存[14]の尺度である。RDCは確率変数の非線形スケーリング[要曖昧さ回避]に関して不変であり、関数に関連した幅広いパターンを発見可能であり、独立では値が0になる。
バイナリ変数[注釈 3]2つの場合、オッズ比はその従属性を測るもので、数値が負になることはなく場合によっては無限大[0, +infty]となる。ユールのY (Yule's Y) やユールのQなどの関連統計は、これを相関のような[-1, 1]の範囲に正規化している。オッズ比は、ロジスティック回帰モデルによって従属変数が離散かつ独立変数が1つ以上あっても構わないモデルケースに一般化されたものである。
相関比、エントロピーに基づく相互情報量、合計相関、二重合計相関、多分相関もまた全て、それらの間のコピュラを考慮することで、より一般的な依存関係を検出しうる機能がある。一方で決定係数は、相関係数を重回帰へと一般化する。
データ分布に対する感度
変数と間の従属度合いは、その変数が表されるスケールに左右されない。つまり、と間の関係性を分析している場合、大半の相関尺度はをa + bXへと をc + dYへと変換したところで影響を受けない(ここでのa, b, c, dは定数で、bとdは正値)。 これは、一部の相関統計ならびにその類似群にも当てはまる。順位相関係数など一部の相関統計は、 やの周辺分布の単調変換に対しても不変である。
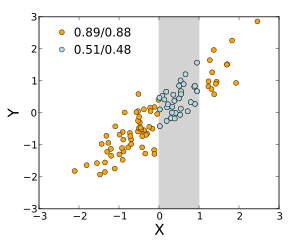
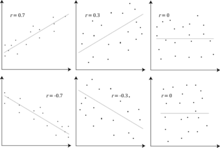
大半の相関尺度は、とが標本採集された手法に大きく反応する。(右図で例示されているように)より広い範囲で値を見たほうが従属関係は強くなる傾向がある。したがって、成人男性全員から父親と息子間における身長の相関係数を考えた場合と、父親の身長を165-170cmに絞った場合に算出される同様の相関係数と比較すると、後者の場合は相関が弱くなる筈である。一方または双方の変数における制限範囲を修正しようとする手法が幾つか開発されており、メタ解析で一般的に使用されている。最も一般的なものが、ソーンダイクによるケースIIとケースIIIの式である[16]。
とにおける特定の同時分布では、使われている様々な相関尺度が定義されない場合もある。例えば、ピアソン相関係数は積率の観点から定義されるため、積率が未定義であれば定義できなくなる。分位数に基づく従属性の尺度は常に定義される。母集団の従属性尺度を推定することを目的とした標本ベースの統計には、データ採集された母集団の空間構造に基づく不偏性であったり漸近的な一貫性(一致性)[17]があるなどの望ましい統計的特性を有する場合もあればそうでない場合もある。
データ分布に対する感度は有益に活用されている。例えば、スケール変換済みの相関 (scaled correlation) は時系列のうち短い期間での相関関係を拾い出す目的でその範囲への感度を調整するように工夫されたものである[18]。規定された方法で値の範囲を縮めることにより、長期間スケールの相関が除外され、短期間スケールの相関のみが明らかとなる。
相関行列
の相関行列の確率変数 はの行列で、その成分はである。したがって、対角成分はすべて等しく1である。 使用される相関の尺度が積率相関係数である場合、相関行列は標準化された確率変数 for の共分散行列と同一である。これは母集団相関行列(その場合は母集団標準偏差)と標本相関行列(この場合 は標本標準偏差を示す)の両方に当てはまる。したがって、各々が半正定値行列である必要性がある。さらに、他の値の線形関数として全ての値を生み出せる変数がない場合、相関行列は厳密に正定値である。








ととが相関関係であり、ととの相関も同じであるため、相関行列は対称である。


相関行列は、例えば重相関係数の場合1つの式の中に現れ、重回帰における適合度の尺度として表示される。
統計モデル構築において、変数間の関係を表す相関行列は異なる相関構造に分類され、推定に必要なパラメータの数などの要因によって区別される。例えば、確率変数が交換可能 (Exchangeable random variables) な相関行列では、変数同士のあらゆるペアが同じ相関を持つものとしてモデル構築されるため、行列の対角以外の成分は全て互いに等しくなる。一方、尺度は時間的に密接している場合に相関が大きくなりがちなので、変数が時系列を表す場合はしばしば自己回帰行列が使用される。
探索的データ解析の相関図 (Iconography of correlations) は相関行列を置き換えたダイアグラムで出来ており、そこでは「顕著な」相関が実線(正の相関)または点線(負の相関)で表されている。
最近傍相関行列
一部の応用(例えば、部分的に観測されたデータだけでデータモデルを構築する)において、相関を近似的に表す行列からそれに最も近い相関行列(例えば、計算方法が原因で通常は半正値の条件を満たさない行列)を見つけたい人もいる[19]。
2002年、ニコラス・ハイアム[20] はフロベニウス標準形を 用いて近傍(nearness)の概念を形式化し、ダイクストラ法を用いて最近傍相関行列を計算する方法を提示した[21]。
これが主題への関心を巻き起こし、その後数年間で新たな理論的成果(例えば、因子構造を用いた近傍行列の算出[22])や数理上の成果(例えば、最近傍相関行列を算出するためにニュートン法を用いる[23])が得られた。
確率過程の無相関と独立
2つの確率過程とについても同様である。仮に両者が独立しているのなら、無相関である[24]:p. 151。この命題の逆が真とは限らない。2変数が無相関だとしても、互いに独立していない場合がある。


よくある誤解
相関と因果
詳細は「相関関係と因果関係」を参照
「多変量正規分布#相関と独立性」も参照
「相関関係は因果関係を含意しない」という慣例的な語句は、相関関係がそれ自体から変数同士の因果関係を推測するのには使えないという意味である[25]。この語句を、相関関係が因果関係の可能性を示すことができないという意味で捉えてはならない。しかし、相関関係の根底にある原因は間接的であったり未知な可能性もあり、高い相関は因果関係が存在しない等号関係(トートロジー)とも重複しうる。それゆえ、2変数間の相関関係は因果関係を(どちら向きにも)確立するだけの十分条件とはならない。
子供の年齢と身長との相関関係はだいぶ因果関係が透明であるが、ヒトの気分と健康との相関関係はそこまでとはいえない。慣用句で「病は気から」とあるが、病気に罹る・罹らないは我々の気分次第なのか? 健やかな気分は健康をもたらすのか? 健康は健やかな気分をもたらすのか? 何か別の要因が両者の根底にあるのではないか?[注釈 4]。 相関関係を因果関係の証拠として採用することは可能だが、どんな相関関係があったとしても因果関係が何であるかを示すことはできない。
単純な線形相関

ピアソン相関係数は2変数間の線形関係の強さを示すが、一般にその値は両者の関係を完全に特徴付けるものではない[27]。特に、の条件付期待値をと置いた場合、示されたが内の線形ではないため、相関係数が完全にはの形に定まらない。

右の図はフランシス・アンスコムによる同一変数の散布図4組 (Anscombe's quartet) を示している[28]。各変数はどれも同じ平均(7.5)、分散(4.12)、相関(0.816)および回帰直線(y = 3 + 0.5x)を有する。しかし、散布図で見られるようにその変数分布は大きく異なる。

左上は正常分布しているように見え、相関があって正規性の仮定に従う2変数を考えた場合に期待される事象に対応しているように思える。右上 は正常分布とは異なるもので、2変数間の明らかな関係性は観察できるが線形ではない。この場合、ピアソン相関係数は厳密な関数的関係の存在を示すことはできず、その関係を線形関係で近似したものを示すに過ぎなくなる。左下では、相関係数を1から0.816に下げてしまうのに十分な影響を及ぼす外れ値1つを除けば、線形関係は完全である。最後の右下は、2変数間の関係が線形でないにもかかわらず、1つの外れ値が高い相関係数を生成するのに十分な例を示したものである。
これらの例は、相関係数が要約統計量 (Summary statistics) としてデータ可視化による検討の代替にならないことを示すものである。これらの例は、ピアソン相関がデータが正規分布に従うことを前提にしていることを示すものと言わたりもするが、これは部分的に正しいに過ぎない[6]。ピアソン相関は、実際に遭遇したほとんどの分布を含む有限共分散行列を持つ分布について正確に計算することができる。ただし、ピアソン相関係数(サンプル平均値および分散値と一緒に取得)は多変量正規分布からデータが引き出された場合に十分統計量となるに過ぎないのである。その結果、ピアソン相関係数は多変量正規分布からデータが引き出された場合にのみ、変数間の関係を完全に特徴付けることになる。
2変量正規分布
詳細は「多変量正規分布」を参照
2つの確率変数が2変量正規分布に従う場合、条件付き平均は,の線形関数である。と間の相関係数は、周辺平均およびとの分散とともに、この線形関係を決定している。



ここでとはそれぞれとの期待値で、とはそれぞれとの標準偏差である。


経験的相関は、相関係数の推定量である。の分布推定量は、以下の式にて求められる。

ここではガウスの超幾何関数でありとなる。この密度がベイズの事後密度であり、正確な最適信頼分布密度でもある[29][30]。


標準誤差
とが確率変数の場合、標準誤差は次の相関と関連性がある。


関連項目
脚注
[脚注の使い方]
注釈
- ^ ピアソン相関係数は線形相関(比例のような関係性)のみに対応しており、正の符号は一方が増加すると他方も増えていく「正の相関」を、負の符号は一方が増加すると他方が減っていく「負の相関」を表す[7]。
- ^ a b 確率論では、各々の変数が独立していない場合に「従属(dependence)」という用語を使う[9]。この従属は「独立でなく何らかの関係性がある」という意味で、相関と同義である。
- ^ 選挙で当選した人は〇、落ちた人は×、のように二つの値だけ(通常0か1)を取る特別な変数のこと。計量経済学などでは「ダミー変数」とも呼ばれる[15]。
- ^ 近年の研究では、大きな精神的ストレスを受けると自律神経のバランスが崩れて免疫力が弱まるため、風邪などの感染症に罹るリスクが高まることが判明している[26]。大きなストレスは気分をかき乱すと共に感染症リスクにも影響を与える、両者に関連した根底の別要因(潜伏変数)だと言える。こうした潜伏要因によって、さも因果関係があるように推測されることを「擬似相関」という。
出典
- ^ コトバンク「相関」精選版 日本国語大辞典の解説より。
- ^ 遠田祐人「相関係数とは何か。その求め方・公式・使い方と3つの注意点」2020年2月9日
- ^ Croxton, Frederick Emory; Cowden, Dudley Johnstone; Klein, Sidney (1968) Applied General Statistics, Pitman. ISBN 9780273403159 (page 625)
- ^ Dietrich, Cornelius Frank (1991) Uncertainty, Calibration and Probability: The Statistics of Scientific and Industrial Measurement 2nd Edition, A. Higler. ISBN 9780750300605 (Page 331)
- ^ Aitken, Alexander Craig (1957) Statistical Mathematics 8th Edition. Oliver & Boyd. ISBN 9780050013007 (Page 95)
- ^ a b Rodgers, J. L.; Nicewander, W. A. (1988). “Thirteen ways to look at the correlation coefficient”. The American Statistician 42 (1): 59-66. doi:10.1080/00031305.1988.10475524. JSTOR 2685263.
- ^ 統計WEB「正の相関と負の相関」2022年1月3日閲覧。
- ^ a b 内閣府統計局「なるほど統計学園 10.特徴を捉える」2022年1月3日閲覧。
- ^ 具体例で学ぶ数学「確率における独立と従属の意味と例」2018年2月5日
- ^ Mahdavi Damghani B. (2013). “The Non-Misleading Value of Inferred Correlation: An Introduction to the Cointelation Model”. Wilmott Magazine 2013 (67): 50-61. doi:10.1002/wilm.10252.
- ^ Sz?kely, G. J. Rizzo; Bakirov, N. K. (2007). “Measuring and testing independence by correlation of distances”. Annals of Statistics 35 (6): 2769?2794. arXiv:0803.4101. doi:10.1214/009053607000000505.
- ^ Sz?kely, G. J.; Rizzo, M. L. (2009). “Brownian distance covariance”. Annals of Applied Statistics 3 (4): 1233-1303. arXiv:1010.0297. doi:10.1214/09-AOAS312. PMC 2889501. PMID 20574547. https://www.ncbi.nlm.nih.gov/pmc/articles/PMC2889501/.
- ^ Lopez-Paz D. and Hennig P. and Sch?lkopf B. (2013). "The Randomized Dependence Coefficient", "Conference on Neural Information Processing Systems" Reprint
- ^ 野澤 勇樹、中村 信弘「確率的依存構造をもつコピュラモデル」『統計数理』第68巻 第1号、統計数理研究所、2020年、87-106頁。コピュラモデルに関しては従属ではなく「依存」という訳語を使っている。意味合いは従属・相関と同じ。
- ^ コトバンク「ダミー変数」世界大百科事典 第2版の解説より
- ^ Thorndike, Robert Ladd (1947). Research problems and techniques (Report No. 3). Washington DC: US Govt. print. off.
- ^ 統計WEB「18-3. 推定量の性質」BellCurve、2022年1月3日閲覧。
- ^ Nikolić, D; Muresan, RC; Feng, W; Singer, W (2012). “Scaled correlation analysis: a better way to compute a cross-correlogram”. European Journal of Neuroscience 35 (5): 1-21. doi:10.1111/j.1460-9568.2011.07987.x. PMID 22324876.
- ^ NAG「最近傍相関行列の計算」2022年1月3日
- ^ Higham, Nicholas J. (2002). “Computing the nearest correlation matrix-a problem from finance”. IMA Journal of Numerical Analysis 22 (3): 329-343. doi:10.1093/imanum/22.3.329.
- ^ “Portfolio Optimizer”. portfoliooptimizer.io/. 2021年1月30日閲覧。
- ^ Borsdorf, Rudiger; Higham, Nicholas J.; Raydan, Marcos (2010). “Computing a Nearest Correlation Matrix with Factor Structure.”. SIAM J. Matrix Anal. Appl. 31 (5): 2603-2622. doi:10.1137/090776718.
- ^ Qi, HOUDUO; Sun, DEFENG (2006). “A quadratically convergent Newton method for computing the nearest correlation matrix.”. SIAM J. Matrix Anal. Appl. 28 (2): 360-385. doi:10.1137/050624509.
- ^ Park, Kun Il (2018). Fundamentals of Probability and Stochastic Processes with Applications to Communications. Springer. ISBN 978-3-319-68074-3
- ^ Aldrich, John (1995). “Correlations Genuine and Spurious in Pearson and Yule”. Statistical Science 10 (4): 364-376. doi:10.1214/ss/1177009870. JSTOR 2246135.
- ^ 大塚製薬「免疫力低下の原因」2022年1月3日閲覧。
- ^ Mahdavi Damghani, Babak (2012). “The Misleading Value of Measured Correlation”. Wilmott Magazine 2012 (1): 64-73. doi:10.1002/wilm.10167.
- ^ Anscombe, Francis J. (1973). “Graphs in statistical analysis”. The American Statistician 27 (1): 17-21. doi:10.2307/2682899. JSTOR 2682899.
- ^ Taraldsen, Gunnar (2021). “The Confidence Density for Correlation” (英語). Sankhya A. doi:10.1007/s13171-021-00267-y. ISSN 0976-8378. https://doi.org/10.1007/s13171-021-00267-y.
- ^ Taraldsen, Gunnar (2020) (英語). Confidence in Correlation. doi:10.13140/RG.2.2.23673.49769. http://rgdoi.net/10.13140/RG.2.2.23673.49769.
- ^ Bowley, A. L. (1928). “The Standard Deviation of the Correlation Coefficient”. Journal of the American Statistical Association 23 (161): 3134. doi:10.2307/2277400. ISSN 0162-1459. https://www.jstor.org/stable/2277400.
- ^ “Derivation of the standard error for Pearson's correlation coefficient”. Cross Validated. 2021年7月30日閲覧。
外部リンク
ウィキメディア・コモンズには、相関に関連するカテゴリがあります。
- 統計WEB「統計学の時間」-26章「相関分析」
- 内閣府統計局「統計学習の指導のために」-総合学習のための補助教材
- MathWorld page on the (cross-)correlation coefficient/s of a sample
- Proof that the Sample Bivariate Correlation has limits plus or minus 1
- Interactive Flash simulation on the correlation of two normally distributed variables by Juha Puranen.
| |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 標本調査 | |||||||||||||||
| 要約統計量 |
| ||||||||||||||
| 推計統計学 |
| ||||||||||||||
| ベイズ統計学 |
| ||||||||||||||
| 相関 |
| ||||||||||||||
| モデル | |||||||||||||||
| 回帰 |
| ||||||||||||||
| 分類 |
| ||||||||||||||
| 教師なし学習 |
| ||||||||||||||
| 統計図表 | |||||||||||||||
| 生存分析 | |||||||||||||||
| 歴史 |
| ||||||||||||||
| 応用 | |||||||||||||||
| 出版物 |
| ||||||||||||||
| 全般 | |||||||||||||||
| その他 | |||||||||||||||
| | |||||||||||||||
| 典拠管理データベース: 国立図書館 |
|
|---|










