| Verallgemeinerte Binomialverteilung |
Wahrscheinlichkeitsfunktion
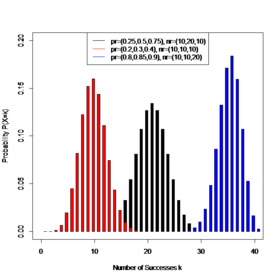 |
Verteilungsfunktion
 |
| Parameter | ![{\displaystyle \mathbf {p} \in [0,1]^{n}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/5233cb53cf328b3491ef7536c5b52e63e6c854a2) — Erfolgswahrscheinlichkeiten für jeden der n Versuche — Erfolgswahrscheinlichkeiten für jeden der n Versuche |
| Träger |  |
| Dichtefunktion |  |
| Verteilungsfunktion |  |
| Erwartungswert |  |
| Varianz |  |
| Schiefe |  |
| Wölbung |  |
| Momenterzeugende Funktion |  |
| Charakteristische Funktion |  |
Die Verallgemeinerte Binomialverteilung (gelegentlich auch Poissonsche Verallgemeinerung der Binomialverteilung, oder Poisson-Binomialverteilung genannt) ist eine Wahrscheinlichkeitsverteilung und somit dem mathematischen Teilgebiet der Stochastik zuzuordnen. Bei ihr handelt es sich um eine univariate diskrete Wahrscheinlichkeitsverteilung. Sie ist definiert als die Summe von unabhängigen, nicht notwendigerweise identisch verteilten Zufallsvariablen, welche einer Bernoulli-Verteilung unterliegen.
Die Verallgemeinerte Binomialverteilung beschreibt also die Erfolge einer Serie von unabhängigen Versuchen, welche jeweils genau zwei Ergebnisse annehmen kann. Der Unterschied zur Binomialverteilung besteht darin, dass jedem Versuch eine andere Erfolgswahrscheinlichkeit zugeordnet werden kann.
Es ist auch möglich die Verallgemeinerte Binomialverteilung als Summe von unabhängigen, nicht identischen, binomialverteilten Zufallsvariablen festzulegen, wobei die Bernoulli Zufallsgrößen mit identischen Erfolgswahrscheinlichkeiten zu binomialverteilten Zufallsvariablen zusammengefasst werden.
Definition der Verallgemeinerten Binomialverteilung
Eine diskrete Zufallsvariable  folgt einer Verallgemeinerten Binomialverteilung mit Parametervektor
folgt einer Verallgemeinerten Binomialverteilung mit Parametervektor  , wenn sie die folgende Wahrscheinlichkeitsfunktion besitzt[1]
, wenn sie die folgende Wahrscheinlichkeitsfunktion besitzt[1]
 ,
,
wobei  den Vektor der Erfolgswahrscheinlichkeiten pro Versuch und
den Vektor der Erfolgswahrscheinlichkeiten pro Versuch und  die Gesamtanzahl der Erfolge bei
die Gesamtanzahl der Erfolge bei  Versuchen bezeichnet.
Versuchen bezeichnet.
Schreibweise: 
 ist die Menge aller -elementigen Teilmengen, die aus dem Träger
ist die Menge aller -elementigen Teilmengen, die aus dem Träger  gebildet werden können.
gebildet werden können.  ist das Komplement von
ist das Komplement von  , das heißt
, das heißt  .
.
Die zugehörige Verteilungsfunktion lautet[2]

Alternative Parametrisierung
Die Verallgemeinerte Binomialverteilung kann ebenso als Summe von binomialverteilten Zufallsgrößen definiert werden, indem die Bernoulli Zufallsvariablen mit gleichen Erfolgswahrscheinlichkeiten zu binomialverteilten Zufallsgrößen zusammengefasst werden.
 ,
,
wobei der Parametervektor  die Erfolgswahrscheinlichkeiten von
die Erfolgswahrscheinlichkeiten von  binomialverteilten Zufallsvariablen enthält und der Parametervektor
binomialverteilten Zufallsvariablen enthält und der Parametervektor  die jeweils zugehörige Anzahl an Versuchen.
die jeweils zugehörige Anzahl an Versuchen.
Es gilt somit  . Hierbei ist
. Hierbei ist  der Einsvektor der Länge
der Einsvektor der Länge  , bestehend aus lauter Einsen.
, bestehend aus lauter Einsen.
Eigenschaften der Verallgemeinerten Binomialverteilung
sei im Folgenden eine Zufallsvariable, die einer Verallgemeinerten Binomialverteilung folgt .
Erwartungswert
Die Verallgemeinerte Binomialverteilung besitzt den Erwartungswert

Varianz
Die Verallgemeinerte Binomialverteilung besitzt die Varianz

Schiefe
Die Verallgemeinerte Binomialverteilung besitzt die Schiefe

Wölbung und Exzess
Die Verallgemeinerte Binomialverteilung besitzt die Wölbung

und damit den Exzess

Kumulanten
Die kumulantenerzeugende Funktion ist
 .
.
Daher ist die k-te Kumulante genau die Summe der k-ten Kumulanten der n Bernoulli-verteilten Zufallsvariablen, aus denen die Verallgemeinerte Binomialverteilung zusammengesetzt ist:

Für diese Kumulanten gilt dann auch die Rekursionsgleichung der Kumulanten der Bernoulli-Verteilung.
Wahrscheinlichkeitserzeugende Funktion
Die wahrscheinlichkeitserzeugende Funktion der verallgemeinerten Binomialverteilung lautet

Charakteristische Funktion
Die charakteristische Funktion der Verallgemeinerten Binomialverteilung lautet:

Momenterzeugende Funktion
Die momenterzeugende Funktion der Verallgemeinerten Binomialverteilung lautet:

Summe von verallgemeinert binomialverteilten Zufallsvariablen
Ist  und
und  zwei unabhängige verallgemeinert binomialverteilte Zufallsvariablen, dann ist auch
zwei unabhängige verallgemeinert binomialverteilte Zufallsvariablen, dann ist auch  verallgemeinert binomialverteilt:
verallgemeinert binomialverteilt:  . Demnach ist die verallgemeinerte Binomialverteilung reproduktiv.
. Demnach ist die verallgemeinerte Binomialverteilung reproduktiv.
Beziehung zu anderen Verteilungen
Beziehung zur Binomialverteilung
Die Summe von voneinander unabhängigen binomialverteilten Zufallsvariablen  ist verallgemeinert binomialverteilt. Wenn alle Erfolgswahrscheinlichkeiten gleich sind, das heißt
ist verallgemeinert binomialverteilt. Wenn alle Erfolgswahrscheinlichkeiten gleich sind, das heißt  , dann ergibt sich aus der Verallgemeinerten Binomialverteilung die Binomialverteilung. Tatsächlich ist die Binomialverteilung für festen Erwartungswert und feste Ordnung diejenige verallgemeinerte Binomialverteilung mit maximaler Entropie.[3] Das bedeutet, unter der Bedingung, dass der Parametervektor von die Länge hat, maximiert
, dann ergibt sich aus der Verallgemeinerten Binomialverteilung die Binomialverteilung. Tatsächlich ist die Binomialverteilung für festen Erwartungswert und feste Ordnung diejenige verallgemeinerte Binomialverteilung mit maximaler Entropie.[3] Das bedeutet, unter der Bedingung, dass der Parametervektor von die Länge hat, maximiert  die Entropie
die Entropie  .
.
Beziehung zur Bernoulli-Verteilung
Die Summe von voneinander unabhängigen Bernoulli-verteilten Zufallsvariablen  , die alle einen unterschiedlichen Parameter
, die alle einen unterschiedlichen Parameter  besitzen, ist verallgemeinert binomialverteilt.
besitzen, ist verallgemeinert binomialverteilt.
Approximation durch die Poisson-Verteilung
Für eine sehr große Anzahl an Versuchen und sehr kleine, aber unterschiedliche Erfolgswahrscheinlichkeiten  kann die Wahrscheinlichkeitsfunktion der Verallgemeinerten Binomialverteilung durch die Poisson-Verteilung approximiert werden.[2]
kann die Wahrscheinlichkeitsfunktion der Verallgemeinerten Binomialverteilung durch die Poisson-Verteilung approximiert werden.[2]

Der Parameter  ist gleich dem Erwartungswert der Verallgemeinerten Binomialverteilung.
ist gleich dem Erwartungswert der Verallgemeinerten Binomialverteilung.
Approximation durch die Normalverteilung
Die Verteilungsfunktion der Verallgemeinerten Binomialverteilung kann für eine sehr große Anzahl an Versuchen durch die Normalverteilung approximiert werden.[2]

Der Parameter  entspricht dem Erwartungswert und
entspricht dem Erwartungswert und  der Standardabweichung der Verallgemeinerten Binomialverteilung.
der Standardabweichung der Verallgemeinerten Binomialverteilung.  ist die Verteilungsfunktion der Standardnormalverteilung.
ist die Verteilungsfunktion der Standardnormalverteilung.
Beispiele
Radarkontrolle
Ein Arbeitnehmer muss an jedem Arbeitstag über die Autobahn und durch das Ortsgebiet zur Arbeit fahren. Die Wahrscheinlichkeiten in eine Radarkontrolle zu geraten sind  auf der Autobahn und
auf der Autobahn und  im Ortsgebiet.
im Ortsgebiet.
Wie hoch sind die Wahrscheinlichkeiten an einem Arbeitstag in  Kontrollen zu geraten?
Kontrollen zu geraten?
Die zufällige Anzahl von Radarkontrollen  kann als Summe von zwei Bernoulli-verteilten Zufallsvariablen
kann als Summe von zwei Bernoulli-verteilten Zufallsvariablen  für die Autobahn und
für die Autobahn und  für das Ortsgebiet modelliert werden:
für das Ortsgebiet modelliert werden:  , mit
, mit


Da und unterschiedliche Erfolgswahrscheinlichkeiten besitzen, kann man dieses Beispiel nicht mit Hilfe der Binomialverteilung lösen.
folgt einer Verallgemeinerten Binomialverteilung mit Parametervektor  .
.
Die gesuchten Wahrscheinlichkeiten können folgendermaßen berechnet werden:
 Kontrollen:
Kontrollen: 

 Kontrolle:
Kontrolle: 

 Kontrollen:
Kontrollen: 

Herstellungsprozess
In einer Fabrik werden Geräte produziert und anschließend einer Qualitätskontrolle unterzogen. Es können  verschiedene Fehlertypen auftreten. Die Wahrscheinlichkeiten, dass ein spezieller Fehlertyp auftritt sind
verschiedene Fehlertypen auftreten. Die Wahrscheinlichkeiten, dass ein spezieller Fehlertyp auftritt sind  für den Fehler vom Typ und jeweils
für den Fehler vom Typ und jeweils  für die Fehlertypen und .
für die Fehlertypen und .
Wie hoch sind die Wahrscheinlichkeiten dafür, dass ein Gerät mit  Fehlern produziert wird?
Fehlern produziert wird?
Die zufällige Anzahl von Fehlern  kann als Summe von drei Bernoulli-verteilten Zufallsvariablen
kann als Summe von drei Bernoulli-verteilten Zufallsvariablen  ,
,  und
und  geschrieben werden:
geschrieben werden:  , mit
, mit


besitzt eine Verallgemeinerten Binomialverteilung mit Parametervektor  .
.
Alternativ kann die Parametrisierung  gewählt werden, indem die identischen Bernoulli Zufallsvariablen zu einer binomialverteilten Zufallsvariable zusammengefasst werden.
gewählt werden, indem die identischen Bernoulli Zufallsvariablen zu einer binomialverteilten Zufallsvariable zusammengefasst werden.
Die gesuchten Wahrscheinlichkeiten können folgendermaßen berechnet werden:
- Fehler:


- Fehler:


- Fehler:


- Fehler:


Anwendung & Berechnung
Die Verallgemeinerte Binomialverteilung kommt in vielen Bereichen zum Einsatz; z. B. Umfragen, Herstellungsprozesse, Qualitätssicherung. Oft wird allerdings eine Approximation benutzt, da die exakte Berechnung sehr aufwändig ist. Ohne entsprechende Software sind selbst einfache Modelle mit wenigen Bernoulli Zufallsvariablen kaum zu berechnen.
Zufallszahlen
Zur Erzeugung von Zufallszahlen kann die Inversionsmethode verwendet werden. Alternativ kann man auch Bernoulli-verteilte Zufallszahlen zu den Parametern erzeugen und diese Aufsummieren. Das Ergebnis ist dann verallgemeinert binomialverteilt.
Literatur
- M.Fisz, Wahrscheinlichkeitsrechnung und mathematische Statistik, VEB Deutscher Verlag der Wissenschaften, 1973, p. 164 ff.
- K.J. Klauer, Kriteriumsorientierte Tests, Verlag für Psychologie, Hogrefe, 1987, Göttingen, p. 208 ff.
Weblinks
- GenBinomApps – R Package. R Package zur Berechnung von Clopper Pearson Konfidenzintervallen und der verallgemeinerten Binomialverteilung. Abgerufen am 30. Juli 2015.
Einzelnachweise
- ↑ On the Number of Successes in Independent Trials. (PDF; 1,6 MB) Y.H.Wang, Statistica Sinica, Vol. 3, 1993, p. 295–312. Abgerufen am 23. September 2013.
- ↑ a b c On Computing the Distribution Function for the Sum of Independent and Non-identical Random Indicators. (Memento vom 23. Oktober 2015 im Internet Archive) (PDF; 110 kB) Y.Hong, Blacksburg, USA, 5. April 2011. Abgerufen am 23. September 2013.
- ↑ Peter Harremoës: Binomial and Poisson Distributions as Maximum Entropy Distributions. In: IEEE Transactions on Information Theory. 47. Jahrgang. IEEE Information Theory Society, 2001, S. 2039–2041, doi:10.1109/18.930936.
Diskrete univariate Verteilungen
Kontinuierliche univariate Verteilungen
Multivariate Verteilungen









