Distribució de Pareto
Funció de densitat de probabilitat  Funcions de densitat de probabilitat de Pareto de tipus I per diferents valors de amb A mesura que la distribució tendeix a on és la funció delta de Dirac. | |
Funció de distribució de probabilitat  Funcions de distribució acumulada de Pareto de tipus I per diferents valors de amb | |
| Tipus | família exponencial, Distribució de cua pesada i Distribució de Pareto generalitzada  |
|---|---|
| Epònim | Vilfredo Pareto |
| Paràmetres | escala (real) escala (real) |
| Suport | |
| fdp | |
| FD | |
| Esperança matemàtica | |
| Mediana | |
| Moda | |
| Variància | |
| Coeficient de simetria | |
| Curtosi | |
| Entropia | |
| FC | |
| Informació de Fisher | Dreta: |
| Mathworld | ParetoDistribution |












![{\displaystyle x_{\mathrm {m} }{\sqrt[{\alpha }]{2}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/ef1a9e02a1d60cf9cd611b13188b078509904bc7)








La distribució de Pareto, que porta el nom de l'enginyer civil, economista i sociòleg Vilfredo Pareto,[1] és una distribució de probabilitat que s'utilitza per descriure diferents fenòmens socials, de control de qualitat, científics, geofísics, actuarials i altres tipus de fenòmens observables. Inicialment es va aplicar en la descripció de la distribució de la riquesa a la societat, ja que encaixava amb la tendència que una gran porció de la riquesa és propietat d'una fracció petita de la població.[2][3] El principi de Pareto o la "regla 80-20" que afirma que "el 80% dels efectes són conseqüència del 20% de les causes" també porta el nom de Pareto, tot i que el concepte és diferent, i només les distribució de Pareto amb paràmetre de forma (α) de log₄5 ≈ 1.16 reflecteixen aquest precís cas. Observacions empíriques han demostrat que aquesta distribució 80-20 encaixa un ampli espectre de casos, inclosos fenòmens naturals[4] i activitats humanes.[5]
Definicions
Sigui X una variable aleatòria que segueix una distribució de Pareto (de tipus I),[6] llavors la probabilitat que X sigui més gran que un cert nombre x, és a dir funció de supervivència ve donada per

on xm és el valor mínim possible (necessàriament positiu) de X, i α és un paràmetre positiu. La distribució de Pareto de tipus I és caracteritzada pel paràmetre d'escala xm i pel paràmetre de forma α, que és conegut com índex de cua (de l'anglès tail index). Quan s'utilitza aquesta distribució per modelar la distribució de la riquesa, llavors el paràmetre α s'anomena índex de Pareto.
Funció de distribució acumulada
A partir de la definició, la funció de distribució acumulada d'una variable aleatòria de Pareto amb paràmetres α i xm és

Funció de densitat de probabilitat
Del resultat anterior se'n desprèn (aplicant la diferenciació) que la funció de densitat de probabilitat és

Quan es representa en eixos lineals, la distribució pren una forma de corba en J i tendeix als eixos ortogonals asimptòticament. Tots els segments de la corba són similars entre ells (més enllà d'un factor d'escala). Quan s'empra la representació logarítmica, la distribució és una línea recta.
Propietats
Moments i funció característica
- L'esperança d'una variable aleatòria que segueix la distribució de Pareto és

- La variància d'una variable aleatòria que segueix una distribució de Pareto és
![{\displaystyle \operatorname {Var} (X)={\begin{cases}\infty &\alpha \in (1,2],\\\left({\frac {x_{\mathrm {m} }}{\alpha -1}}\right)^{2}{\frac {\alpha }{\alpha -2}}&\alpha >2.\end{cases}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/bda6ae1a69ab2c130545abd2053226a4d6510558)
- (Si α ≤ 1, la variància no existeix.)
- Els moments són

- La funció generadora de moments només és definida per valors no positius de t ≤ 0 com
![{\displaystyle M\left(t;\alpha ,x_{\mathrm {m} }\right)=\operatorname {E} \left[e^{tX}\right]=\alpha (-x_{\mathrm {m} }t)^{\alpha }\Gamma (-\alpha ,-x_{\mathrm {m} }t)}](https://wikimedia.org/api/rest_v1/media/math/render/svg/0b03963721b9c85e5030aa7a26056af4ef07a4e4)

- La funció característica ve donada per

- on Γ(a, x) és la funció gamma incompleta.
Es poden resoldre els paràmetres usant el mètode dels moments.[7]
Mitjana geomètrica
La mitjana geomètrica (G) és[8]

Mitjana harmònica
La mitjana harmònica (H) és[8]

Representació gràfica
La distribució corbada amb forma de 'llarga cua' característica que s'obté quan es representa en escala lineal emmascara la simplicitat subjacent de la funció quan es representa logarítmicament, cas en què es mostra com una línea recta amb pendent negatiu. Deriva de la fórmula de la funció de densitat de probabilitat que, per x ≥ xm,

Com que α és positiu, el gradient −(α + 1) és negatiu.
Distribucions relacionades
Distribucions generalitzades de Pareto
Existeix una jerarquia[6][9] de les distribucions de Pareto conegudes com Tipus I, II, III, IV, i la distribució de Feller–Pareto.[6][9][10] La distribució de Pareto de Tipus IV conté les distribucions de Pareto de Tipus I–III com a casos particulars. La distribució de Feller–Pareto[9][11] generalitza la distribució de Pareto de Tipus IV.
Pareto de tipus I-IV
La jerarquia de les diferents distribucions de Pareto és resumida en la següent taula, en què es comparen les diferents funcions de supervivència.
Quan μ = 0, la distribució de Pareto de Tipus II és també coneguda com la distribució Lomax.[12]
En aquesta secció, el símbol xm, utilitzat prèviament per indicar el valor mínim de x, és substituït per σ.
| Dominii | Paràmetres | ||
|---|---|---|---|
| Tipus I | |||
| Tipus II | |||
| Lomax | |||
| Tipus III | |||
| Tipus IV |

![{\displaystyle \left[{\frac {x}{\sigma }}\right]^{-\alpha }}](https://wikimedia.org/api/rest_v1/media/math/render/svg/debc11c1d4259755203a2e95e5171e4b2c28b695)


![{\displaystyle \left[1+{\frac {x-\mu }{\sigma }}\right]^{-\alpha }}](https://wikimedia.org/api/rest_v1/media/math/render/svg/c1c05d4c866664355381925ebc7f1d6854a8b4b2)


![{\displaystyle \left[1+{\frac {x}{\sigma }}\right]^{-\alpha }}](https://wikimedia.org/api/rest_v1/media/math/render/svg/b5f6d8660cc815594ad3f6fbbba08e57eaa4bf12)

![{\displaystyle \left[1+\left({\frac {x-\mu }{\sigma }}\right)^{1/\gamma }\right]^{-1}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/08d45a24039951a4a164feb7f48ee05c3b852a28)

![{\displaystyle \left[1+\left({\frac {x-\mu }{\sigma }}\right)^{1/\gamma }\right]^{-\alpha }}](https://wikimedia.org/api/rest_v1/media/math/render/svg/a95750fc2c1674af87b4f4d3115af6dbf9728743)

El paràmetre de forma α és l'índex de cua, μ és la ubicació, σ és l'escala, γ és un paràmetre de desigualtat. Alguns casos particulars de la distribució de Pareto de Tipus IV són



El fet que la mitjana sigui finita i que existeixi la variància i sigui també finita depèn de l'índex de cua α (índex de desigualtat γ). En particular, es mostren a continuació els moments d'ordre δ, que són finits per certs valors de δ > 0, as shown in the table below, on δ no és necessàriament un nombre enter.
| Condició | Condició | |||
|---|---|---|---|---|
| Tipus I | ||||
| Tipus II | ||||
| Tipus III | ||||
| Tipus IV |
![{\displaystyle \operatorname {E} [X]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/44dd294aa33c0865f58e2b1bdaf44ebe911dbf93)
![{\displaystyle \operatorname {E} [X^{\delta }]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/fab8f72a2621c18717c6afbb3a3772ca30a36b4d)















Distribució de Feller-Pareto
William Feller[9][11] va definir la variable de Pareto a partir de la transformació U = Y−1 − 1 d'una variable aleatòria beta Y, que té com a funció de densitat de probabilitat és

on B( ) és la funció beta. Si

llavors W segueix una distribució de Feller–Pareto FP(μ, σ, γ, γ1, γ₂).[6]
Si i són variables Gamma independents, una altra possible construcció d'una variable aleatòria de Feller–Pareto (FP) és[13]



i s'escriu W ~ FP(μ, σ, γ, δ1, δ₂). Casos especials de distribucions de Feller–Pareto són




Relació amb la distribució exponencial
La distribució de Pareto està relacionada amb la distribució exponencial. Sigui X una distribució de Pareto amb valor mínim xm i índex α, llavors

està distribuïda exponencialment amb paràmetre α. Equivalentment, si Y està distribuïda exponencialment amb paràmetre α, llavors

està distribuïda segons Pareto amb mínim xm i índex α.
Això es pot demostrar utilitzant tècniques estàndard de canvi de variable:

La darrera expressió és la funció de distribució acumulada de la distribució exponencial amb paràmetre α.
Es pot construir la distribució de Pareto a parrtir de distribucions exponencials jeràrquiques.[14] Sigui
.

Llavors, .

Relació amb la distribució log-normal
La distribució de Pareto i la distribució log-normal són distribucions alternatives per descriure els mateixos tipus de quantitats. Una de les connexions que hi ha entre elles és que les dues són distribucions que es poden expressar com l'exponenciació d'altres distribucions comunes, de la distribució exponencial i de la distribució normal respectivament. (Vegeu la secció anterior).
Relació amb la distribució generalitzada de Pareto
La distribució de Pareto és un cas particular de la distribució generalitzada de Pareto, que és una família de distribucions que tenen una forma similar, però conté un paràmetre extra de tal forma que el domini de la distribució és o bé fitada per baix (en un punt variable), o bé fitada tant per baix com per dalt (totes dues fites són variables), amb la distribució Lomax com a cas particular. Aquesta família també conté les distribucions exponencials desplaçada i no desplaçada.
La distribució de Pareto amb paràmetre d'escala i paràmetre de forma és equivalent a la distribució generalitzada de Pareto amb paràmetre d'ubicació , paràmetre d'escala i paràmetre de forma . Vice versa, es pot obtenir la distribució de Pareto a partir de la distribució generalitzada de Pareto amb i .






Distribució fitada de Pareto
| Tipus | família exponencial, Distribució de cua pesada i Distribució de Pareto generalitzada |
|---|---|
| Epònim | Vilfredo Pareto |
| Paràmetres | ubicació (real) ubicació (real) |
| Suport | |
| fdp | |
| FD | |
| Esperança matemàtica | |
| Mediana | |
| Variància | (aquest és el segon moment, no la variància) |
| Coeficient de simetria | (aquest és el moment k-èssim, no l'asimetria) |
| Mathworld | ParetoDistribution |











La distribució fitada (o truncada) de Pareto té tres paràmetres: α, L i H. Com en la distribució estàndard de Pareto, α determina la forma. L denota el valor mínim i H el valor màxim.
La funció de densitat de probabilitat de la distribució fitada de Pareto és
- ,
on L ≤ x ≤ H i α > 0.
Variables aleatòries que generen distribucions fitades de Pareto
Sigui U una istribució uniforme en (0, 1), llavors, aplicant el mètode de la transformada inversa


és una distribució fitada de Pareto.
Distribució simètrica de Pareto
L'objectiu de la distribució simètrica de Pareto i de la distribució zero simètrica de Pareto és capturar algunes distribucions estadístiques especials amb un pic afilat de probabilitat i amb cues de probabilitat simètriques i llargues. Aquestes dues distribucions deriven de la distribució de Pareto. Les cues llargues de probabilitat signifiquen que la probabilitat decau lentament. En molts casos, la distribució de Pareto s'utilitza per ajustar corbes. Però si la distribució té una estructura simètrica amb dues cues que decauen lentament, la distribució de Pareto ja no serveix. És llavors quan s'utilitzen les distribucions simètrica i zero simètrica de Pareto.[15]
La funció de distribució acumulada de la distribució de Pareto és definida com:[15]

La funció de densitat de probabilitat corresponent és:[15]

La distribució té dos paràmetres: a i b. És simètrica respecte b. Llavors, l'esperança matemàtica és b. La variància és

La funció de distribució acumulada de la distribució zero simètrica de Pareto és definida com

Amb funció de densitat de probabilitat

Aquesta distribució és simètrica respecte el zero. El paràmetre està relacionat amb la taxa de caiguda de la probabilitat i representa la magnitud pic de probabilitat.[15]
Distribució conjunta de Pareto
La distribució (univariable) de Pareto es pot estendre a la distribució conjunta (multivariable) de Pareto.[16]
Inferència estadística
Estimació de paràmetres
La funció de versemblança dels paràmetre de la distribució de Pareto α i xm, donada una mostra independent x = (x1, x₂, ..., xn), és

Per tant, la funció logarítmica de versemblança és

Es pot notar que és monòtonament ascendent amb xm, és a dir, com més gran és el valor de xm, més gran serà el valor de la funció de versemblança. Per tant, com que x ≥ xm, es pot concloure que


Per trobar un estimador per α, es calcula la derivada parcial corresponent i es determina quan és igual a zero:

Per tant, l'estimador de màxima versemblança per α és:

L'esperança de l'error estadístic és:[17]

Malik (1970)[18] va donar la distribució conjunta exacta de . En particular, i són independents i és una distribució de Pareto amb paràmetre d'escala xm i paràmetre de forma nα, mentre segueix una distribució gamma-inversa amb paràmetres de forma i d'escala n − 1 i nα, respectivament.



Aparició i aplicacions
General
Vilfredo Pareto va utilitzar inicialment aquesta distribució per descriure la distribució de la riquesa entre els individus ja que semblava representar molt bé la manera com una porció gran de la riquesa en tota societat és propietat d'un percentatge petit de la població. També la va usar per desciure la distribució dels ingressos.[3] La idea és sovint expressada simplement com el principi de Pareto o la "regla del 80-20" que diu que el 20% de la població controla el 80% de la riquesa.[19] Tanmateix, la regla del 80-20 correspon a un valor particular de α, i de fet, les dades de Pareto dels impostos dels ingressos a Gran Bretanya en el seu Cours d'économie politique indiquen que al voltant del 30% de la població tenia el 70% dels ingressos. La gràfica de la funció de densitat de probabilitat al principi de l'article mostra que la "probabilitat" o fracció de la població que té una quantitat determinada de riquesa (per persona) és més aviat alta quan la quantitat de riquesa és baixa, i que aquesta fracció disminueix de forma contínua a mesura que la riquesa per persona augmenta. Aquesta distribució no es limita a desciure la riquesa o els ingressos, sinó que també es troba en moltes situacions en què es troba un equilibri en la distribució entre allò "petit" i allò "gran". Els següents exemples sovint es considera que segueixen distribucions de Pareto:
- Les mides dels assentaments (hi ha poques ciutats i molts llogarets i pobles)[20][21]
- La distribució de la mida dels arxius en el tràfic a Internet que utilitza el protocol TCP (hi ha molts més fitxers petits que grans)[20]
- Taxes d'error dels discs durs[22]
- Clústers de condensats de Bose-Einstein a prop del zero absolut[23]

- Les reserves de petroli en els jaciments (hi ha pocs jaciments grans i molts de petits)[20]
- La distribució en temps computacional de les tasques que fan els supercomputadors (algunes poques de llargues, la majoria curtes)[24]
- El preu estàndard de retorn a la borsa[20]
- La mida de les partícules de sorra[20] així com la mida dels meteorits.
- La severitat de les grans pèrdues en baixes en certes línies de negoci des de responsabilitat genereal, fins a auto comercial i compensació laboral.[25][26]
- En hidrologia, s'aplica la distribució de Pareto en els esdeveniments extrems com ara la precipitació diària màxima en un any i les descàrregues dels rius.[27] La figura blava il·lustra un exemple d'ajust de la distribució de Pareto de les precipitacions diàries màximes en un any que mostra també un interval de confiança del 90%, basat en la distribució binomial.
Relació amb la llei de Zipf
La distribució de Pareto és una distribució contínua de probabilitat. La llei de llei de Zipf, també anomenada sovint distribució zeta, és una distirbució discreta que separa els valors en una simple classificació de rangs. Totes dues són una llei de potències amb exponent negatiu, escalats per tal que la seva distribució acumulada sigui igual a 1. Es pot derivar la llei de Zipf de la distribució de Pareto si els valors de (els ingressos) són agrupats en barres talment que el nombre de persones en cada barra segueixi un patró d'1/rang. La distribució és normalitzada definint tal que on és el nombre harmònic generalitzat. Això fa que la funció de densitat de probabilitat de Zipf es pugui derivar de la de Pareto.





on i és un enter que representa el rang d'1 a N, on N és el grup amb ingressos més alts. Així doncs, una persona seleccionada aleatòriament (o una paraula, un enllaç web, una ciutat...) d'una població (o d'una llengua, d'Internet, d'un país...) té una probabilitat de valdre .


Relació amb el "principi de Pareto"
La "llei del 80-20", segons la qual el 20% de les persones més riques obtenen el 80% dels ingressos i que el 20% del 20% de les persones més riques obtenen el 80% del 80% dels ingressos i així successivament aplica exactament quan l'índex val . Es pot derivar aquest resultat a partir de la fórmula de la corba de Lorenz, que s'introdueix més endavant. A més, s'ha demostrat que les següents afirmacions[28] són matemàticament equivalents:

- Els ingressos estan distribuïts seguint una distribució de Pareto amb índex α > 1.
- Existeix un cert nombre 0 ≤ p ≤ 1/2 tal que el 100p % de la gent rep 100(1 − p)% dels ingressos, i similarment, per tot nombre real (no necessàriament enter) n > 0, el 100pn % de tota la gent reben el 100(1 − p)n percent dels ingressos. α i p estan relacionades segons

Això no només aplica als ingressos, sinó també a la riquesa i a tot allò que es pugui modelar amb aquesta distribució.
Aquí s'exclouen les distribucions en què 0 < α ≤ 1, que, com s'ha notat més amunt, tenen una esperança d'infinit, i per tant no poden modelar raonablement les distribucions d'ingressos.
Relació amb la llei de Price
De vegades s'ofereix la llei de Price com a propietat o com una distribució similar a la de Pareto. Tanmateix, la llei només aplica en el cas . Noti's que en aquest cas, la quantitat total i l'esperança de la riquesa no estan definides, i la regla només aplica asimptòticament en mostres aleatòries. El principi estès de Pareto, mencionat més amunt, és una regla molt més general.

Corba de Lorenz i coeficient Gini
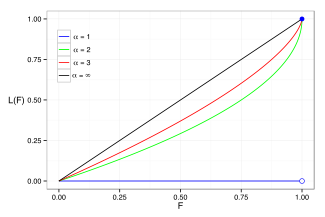
Sovint s'utilitza la corba de Lorenz per caracteritzar els ingreessos i la distribució de la riquesa. En tota distribució, s'escriu la corba de Lorenz L(F) en termes de la funció de distribució f o de la funció de distribució acumulada Fcom

on x(F) és l'inversa de la funció de distribució acumulada. Per la distribució de Pareto,

i la corba de Lorenz es calcula com

Per el denominador és infinit i per tant L=0. En la gràfica de la dreta es mostren exemples de la corba de Lorenz per unes quantes distribucions de Pareto.

Segons Oxfam (2016) les 62 persones més riques tenen tanta riquesa com la meitat més pobra de la població mundial.[29] Es pot estimar l'índex de Pareto que hi hauria en aquesta situació. Sigui ε igual a es té:


o

La solució és que α és igual a 1.15, i al voltant del 9% de la riquesa és propietat de cadascun dels dos grups. Però de fet, el 69% de la població mundial adulta té només un 3% de la riquesa.[30]
El coeficient de Gini mesura la desviació de la corba de Lorenz de la línia d'equidistribució que és una línea que connecta [0, 0] i [1, 1], que es mostra de color negre (α = ∞) en la gràfica de la corba de Lorenz de la dreta. En particular, el coeficient de Gini és dues vegades l'àrea entre la corba de Lorenz i la línea d'equidistribució. El coeficient de Gini de la distribució de Pareto és doncs calculat (per ) com


(vegeu Aaberge 2005).
Mètodes computacionals
Generació de mostres aleatòries
Es poden generar mostres aleatòries utilitzant el mètode de la transformada inversa. Donada una variable aleatòria U que segueix una distribució uniforme en l'interval unitari (0, 1], la variable T, definida com

segueix una distribució de Pareto.[31] Si U està uniformement distribuïda en l'interval [0, 1), es pot intercanviar per (1 − U).
Referències
- ↑ Amoroso, Luigi «VILFREDO PARETO». Econometrica (Pre-1986); Jan 1938; 6, 1; ProQuest, 6, 1938.
- ↑ Pareto, Vilfredo «Cours d'economie politique». Journal of Political Economy, 6, 1898. DOI: 10.1086/250536.
- ↑ 3,0 3,1 Pareto, Vilfredo, Cours d'Économie Politique: Nouvelle édition par G.-H. Bousquet et G. Busino, Librairie Droz, Geneva, 1964, pp. 299–345. Original book archived
- ↑ VAN MONTFORT, M.A.J. «The Generalized Pareto distribution applied to rainfall depths». Hydrological Sciences Journal, 31, 2, 1986, pàg. 151-162. DOI: 10.1080/02626668609491037.
- ↑ Oancea, Bogdan «Income inequality in Romania: The exponential-Pareto distribution». Physica A: Statistical Mechanics and Its Applications, 469, 2017, pàg. 486–498. Bibcode: 2017PhyA..469..486O. DOI: 10.1016/j.physa.2016.11.094.
- ↑ 6,0 6,1 6,2 6,3 Barry C. Arnold. Pareto Distributions. International Co-operative Publishing House, 1983. ISBN 978-0-89974-012-6.
- ↑ S. Hussain, S.H. Bhatti (2018). Parameter estimation of Pareto distribution: Some modified moment estimators. Maejo International Journal of Science and Technology 12(1):11-27
- ↑ 8,0 8,1 Johnson NL, Kotz S, Balakrishnan N (1994) Continuous univariate distributions Vol 1. Wiley Series in Probability and Statistics.
- ↑ 9,0 9,1 9,2 9,3 Johnson, Kotz, and Balakrishnan (1994), (20.4).
- ↑ Christian Kleiber; Samuel Kotz Statistical Size Distributions in Economics and Actuarial Sciences. Wiley, 2003. ISBN 978-0-471-15064-0.
- ↑ 11,0 11,1 Feller, W. An Introduction to Probability Theory and its Applications. II. 2nd. Nova York: Wiley, 1971, p. 50. "The densities (4.3) are sometimes called after the economist Pareto. It was thought (rather naïvely from a modern statistical standpoint) that income distributions should have a tail with a density ~ Ax−α as x → ∞."
- ↑ Lomax, K. S. «Business failures. Another example of the analysis of failure data». Journal of the American Statistical Association, 49, 268, 1954, pàg. 847–52. DOI: 10.1080/01621459.1954.10501239.
- ↑ Chotikapanich, Duangkamon. «Chapter 7: Pareto and Generalized Pareto Distributions». A: Modeling Income Distributions and Lorenz Curves, 16 setembre 2008, p. 121–22. ISBN 9780387727967.
- ↑ (tesi). section 5.3.1
- ↑ 15,0 15,1 15,2 15,3 Huang, Xiao-dong «A Multiscale Model for MPEG-4 Varied Bit Rate Video Traffic». IEEE Transactions on Broadcasting, 50, 3, 2004, pàg. 323–334. DOI: 10.1109/TBC.2004.834013.
- ↑ Rootzén, Holger; Tajvidi, Nader «Multivariate generalized Pareto distributions». Bernoulli, 12, 2006, pàg. 917–30. DOI: 10.3150/bj/1161614952.
- ↑ M. E. J. Newman «Power laws, Pareto distributions and Zipf's law». Contemporary Physics, 46, 5, 2005, pàg. 323–51. arXiv: cond-mat/0412004. Bibcode: 2005ConPh..46..323N. DOI: 10.1080/00107510500052444.
- ↑ H. J. Malik «Estimation of the Parameters of the Pareto Distribution». Metrika, 15, 1970, pàg. 126–132. DOI: 10.1007/BF02613565.
- ↑ For a two-quantile population, where approximately 18% of the population owns 82% of the wealth, the Theil index takes the value 1.
- ↑ 20,0 20,1 20,2 20,3 20,4 Reed, William J.; etal «The Double Pareto-Lognormal Distribution – A New Parametric Model for Size Distributions». Communications in Statistics – Theory and Methods, 33, 8, 2004, pàg. 1733–53. DOI: 10.1081/sta-120037438.
- ↑ Reed, William J. «On the rank‐size distribution for human settlements». Journal of Regional Science, 42, 1, 2002, pàg. 1-17. DOI: 10.1111/1467-9787.00247.
- ↑ Schroeder, Bianca; Damouras, Sotirios; Gill, Phillipa «Understanding latent sector error and how to protect against them». 8th Usenix Conference on File and Storage Technologies (FAST 2010), 24-02-2010 [Consulta: 10 setembre 2010]. «We experimented with 5 different distributions (Geometric,Weibull, Rayleigh, Pareto, and Lognormal), that are commonly used in the context of system reliability, and evaluated their fit through the total squared differences between the actual and hypothesized frequencies (χ² statistic). We found consistently across all models that the geometric distribution is a poor fit, while the Pareto distribution provides the best fit.»
- ↑ Yuji Ijiri; Simon, Herbert A. «Some Distributions Associated with Bose–Einstein Statistics». Proc. Natl. Acad. Sci. USA, 72, 5, maig 1975, pàg. 1654–57. Bibcode: 1975PNAS...72.1654I. DOI: 10.1073/pnas.72.5.1654. PMC: 432601. PMID: 16578724.
- ↑ Harchol-Balter, Mor; Downey, Allen «Exploiting Process Lifetime Distributions for Dynamic Load Balancing». ACM Transactions on Computer Systems, 15, 3, agost 1997, pàg. 253–258. DOI: 10.1145/263326.263344.
- ↑ Kleiber and Kotz (2003): p. 94.
- ↑ Seal, H. «Survival probabilities based on Pareto claim distributions». ASTIN Bulletin, 11, 1980, pàg. 61–71. DOI: 10.1017/S0515036100006620.
- ↑ CumFreq, software for cumulative frequency analysis and probability distribution fitting [1]
- ↑ Hardy, Michael «Pareto's Law». Mathematical Intelligencer, 32, 3, 2010, pàg. 38–43. DOI: 10.1007/s00283-010-9159-2.
- ↑ «62 people own the same as half the world, reveals Oxfam Davos report». Oxfam, Jan 2016.
- ↑ «Global Wealth Report 2013» p. 22. Credit Suisse, Oct 2013. Arxivat de l'original el 2015-02-14. [Consulta: 24 gener 2016]. Arxivat 2015-02-14 a Wayback Machine.
- ↑ Tanizaki, Hisashi. Computational Methods in Statistics and Econometrics. CRC Press, 2004, p. 133. ISBN 9780824750886.
Bibliografia
- M. O. Lorenz «Methods of measuring the concentration of wealth». Publications of the American Statistical Association, 9, 70, 1905, pàg. 209–19. Bibcode: 1905PAmSA...9..209L. DOI: 10.2307/2276207. JSTOR: 2276207.
- Pareto, Vilfredo. Librairie Droz. Ecrits sur la courbe de la répartition de la richesse, 1965, p. 48. ISBN 9782600040211.
- Pareto, Vilfredo «La legge della domanda». Giornale Degli Economisti, 10, 1895, p. 59–68.
- Pareto, Vilfredo. Cours d'économie politique, 1896. DOI 10.1177/000271629700900314.
Vegeu també
Enllaços externs
- Michiel Hazewinkel (ed.). Pareto distribution. Encyclopedia of Mathematics (en anglès). Springer, 2001. ISBN 978-1-55608-010-4.
- Weisstein, Eric W., «Pareto distribution» a MathWorld (en anglès).
- Aabergé, Rolf. [https://web.archive.org/web/20200420080507/http://www3.unisi.it/eventi/GiniLorenz05/25%20may%20paper/PAPER_Aaberge.pdf Arxivat 2020-04-20 a Wayback Machine. Gini's Nuclear Family], maig 2005.
- (desembre 1997) "Self-Similarity in World Wide Web Traffic: Evidence and Possible Causes" a IEEE/ACM Transactions on Networking. 5: 835–846 [Consulta: 17 març 2021] Arxivat 2016-03-04 a Wayback Machine.
| Distribucions discretes amb suport finit | |
|---|---|
| Distribucions discretes amb suport infinit | |
| Distribucions contínues suportades sobre un interval acotat |
|
| Distribucions contínues suportades sobre un interval semi-infinit |
|
| Distribucions contínues suportades en tota la recta real |
|
| Distribucions contínues amb el suport de varis tipus |
|
| Barreja de distribució variable-contínua | |
| Distribució conjunta |
|
| Direccionals |
|
| Degenerada i singular |
|
| Famílies |
|

